
|
|---|
|
|
|
これは日々の作業を通して学んだことや毎日の生活で気づいたことをを記録しておく備忘録である。
HTML ファイル生成日時: 2026/07/16 23:23:49.686 (台灣標準時)
Beautiful Soup を使って HTML ファイルの中から必要な情報を抽出する方法を調べてみたでござる。
まず、 NHK のニュース記事から、記事の題名と本文を抽出する、ということ を試してみたでござる。 HTML ファイルを見てみると、 <h1 class="content--title"> と </h1> で囲まれた部分に記事の題名が あり、 <div class="content--detail-body"> と </div> で囲ま れた部分に記事の本文があるようでござる。
|
|
|---|
|
|
|
|
|
|
そこで、以下のようなプログラムを書いてみたでござる。
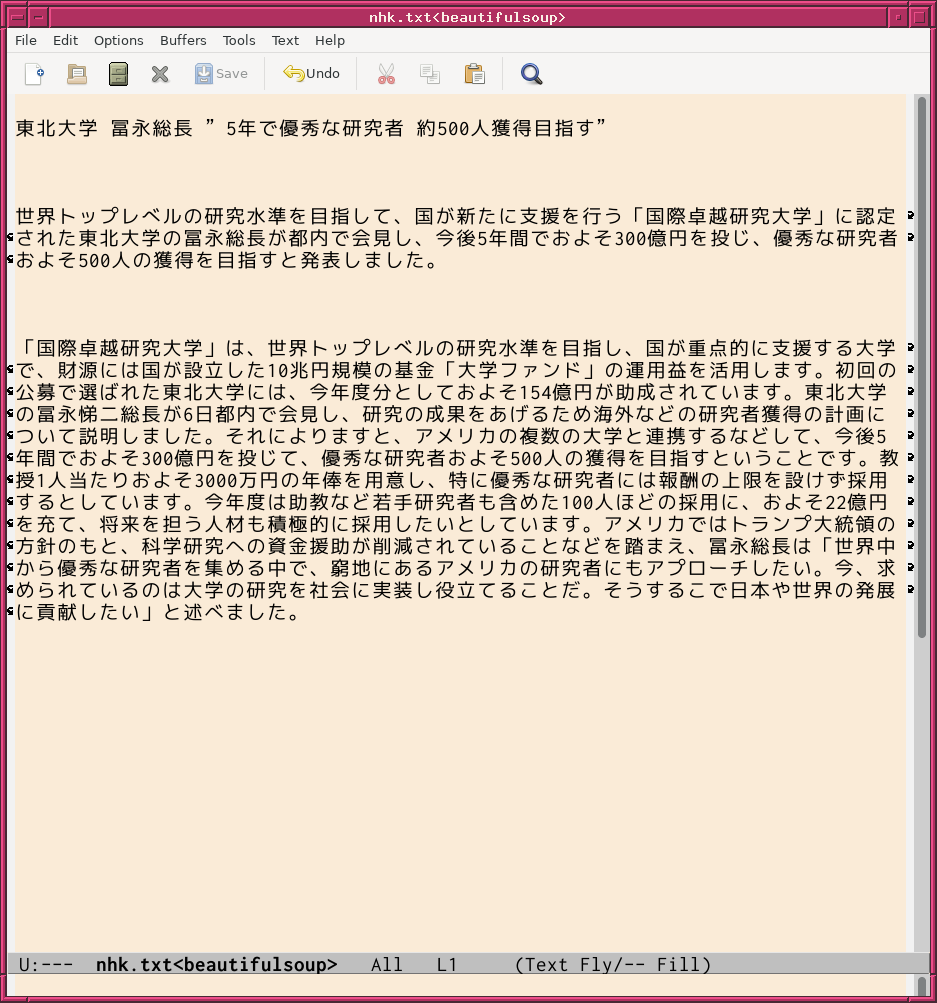
#!/usr/pkg/bin/python3.13 # # Time-stamp: <2025/06/06 18:10:00 (UT+08:00) daisuke> # # importing urllib module import urllib.request # importing beautiful soup module import bs4 # URL url_nhk = 'https://www3.nhk.or.jp/news/html/20250606/k10014827981000.html' # output file name file_text = 'nhk.txt' # fetching HTML file with urllib.request.urlopen (url_nhk) as fh: html_nhk = fh.read ().decode ('utf-8') # creating BeautifulSoup object soup = bs4.BeautifulSoup (html_nhk, 'html.parser') # extracting article title and body html_article_title = soup.find ('h1', class_='content--title') html_article_body = soup.find ('div', class_='content--detail-body') # opening file for writing with open (file_text, 'w') as fh_out: fh_out.write (html_article_title.get_text ()) fh_out.write (f'\n\n') fh_out.write (html_article_body.get_text ())
すると、期待通りに動作してくれて、記事の題名と本文が書かれたテキストファ イルが作られたでござる。
|
|---|
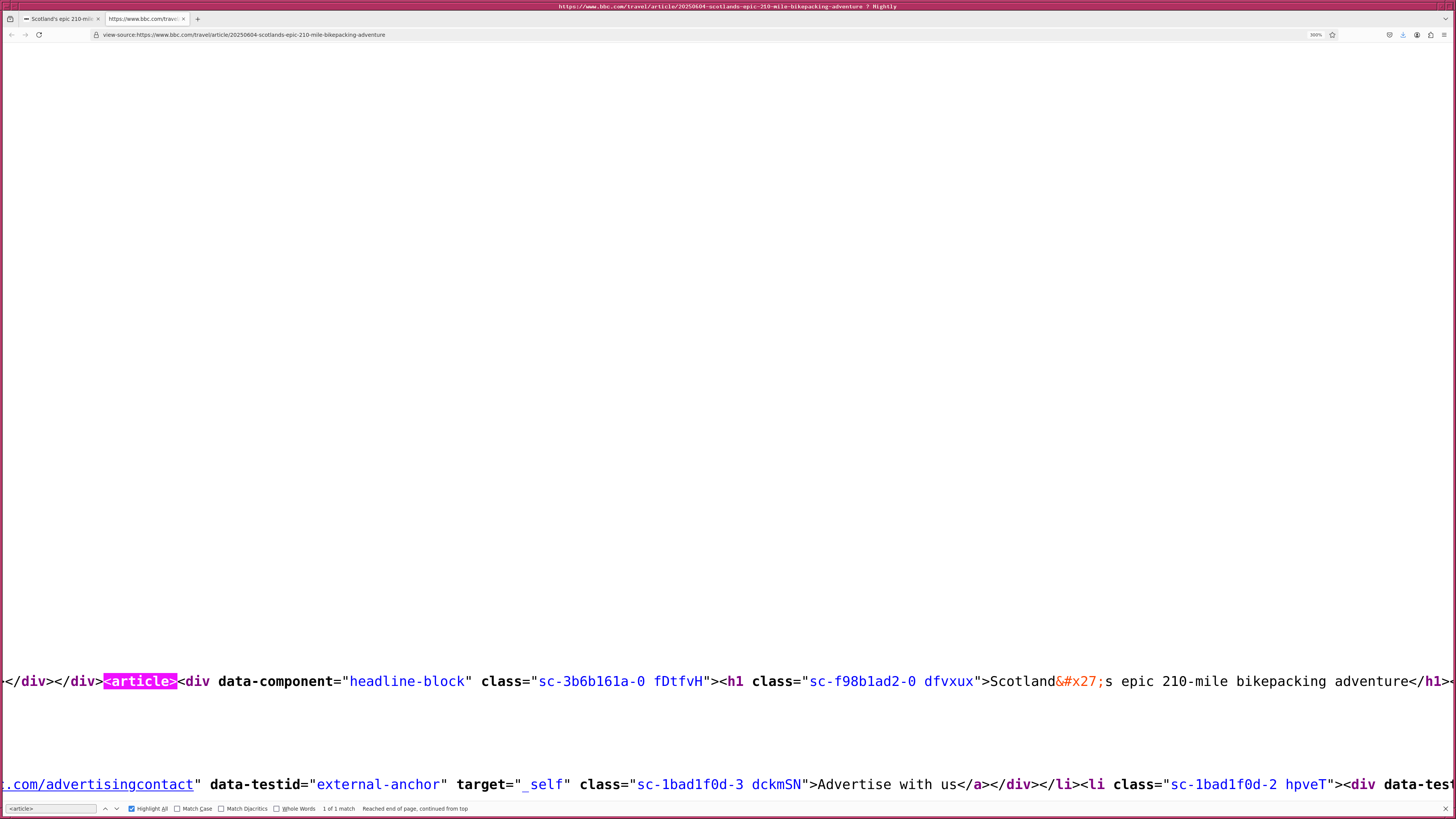
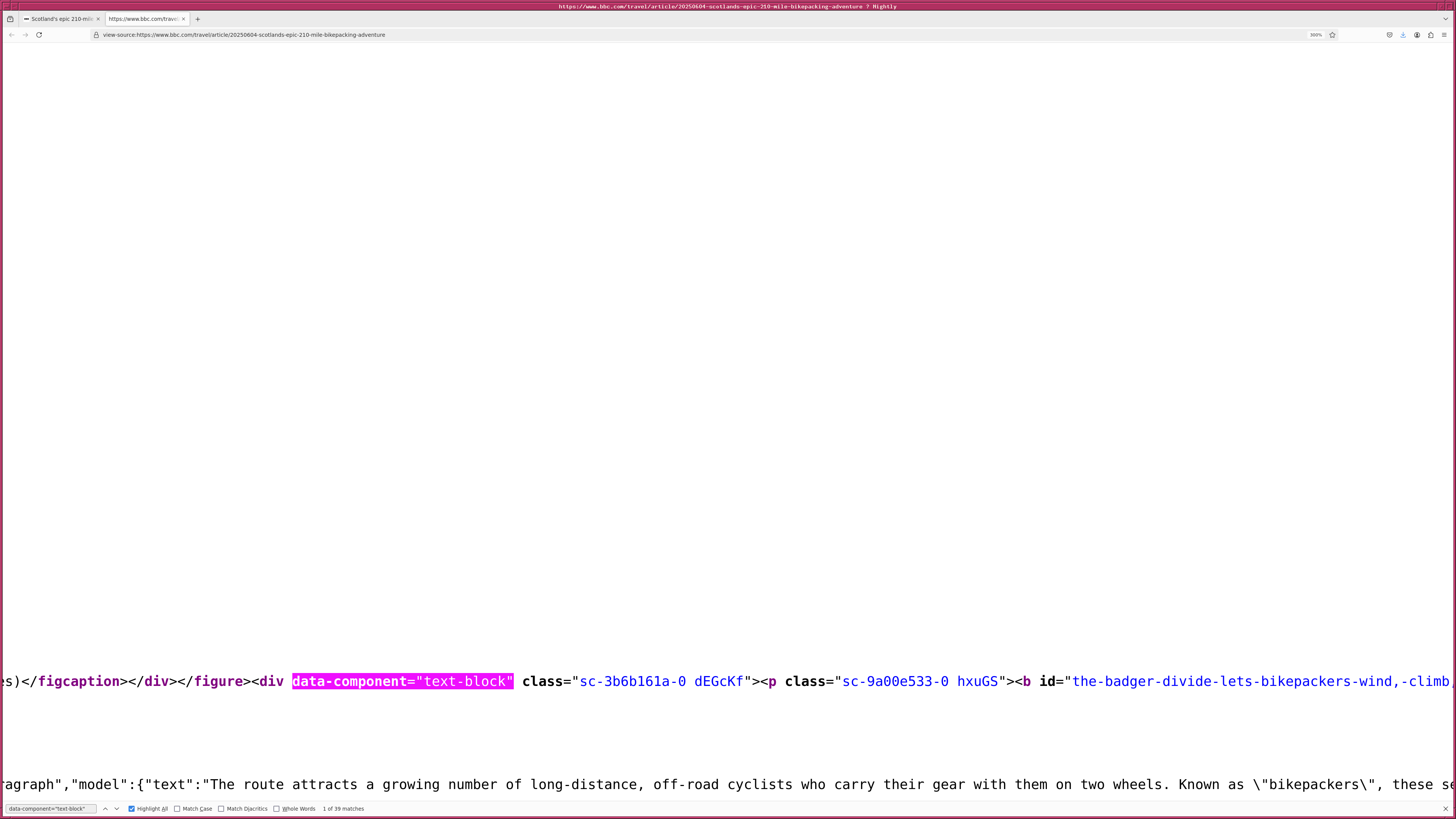
次に、 BBC の記事から題名と本文を抽出するプログラムを作ってみることに したでござる。 HTML ファイルを見てみると、 <article> タグの中に ある <h1> タグを探せば記事の題名が見つかるようでござる。また、記 事の本文は <div data-component="text-block"> というところを見つ ければよいようでござる。ただし、記事の本文が格納されている <div> タグは一つだけでなく、複数あるようでござる。 .find () ではなく、 .find_all () を使う必要があるようでござる。また、 data-component で指 定されている値を見るためには、 .find_all (attrs={"data-component": "text-block"}) と使えばよいようでござる。

|
|---|
|
|
|
以下のようなプログラムを作ってみたでござる。
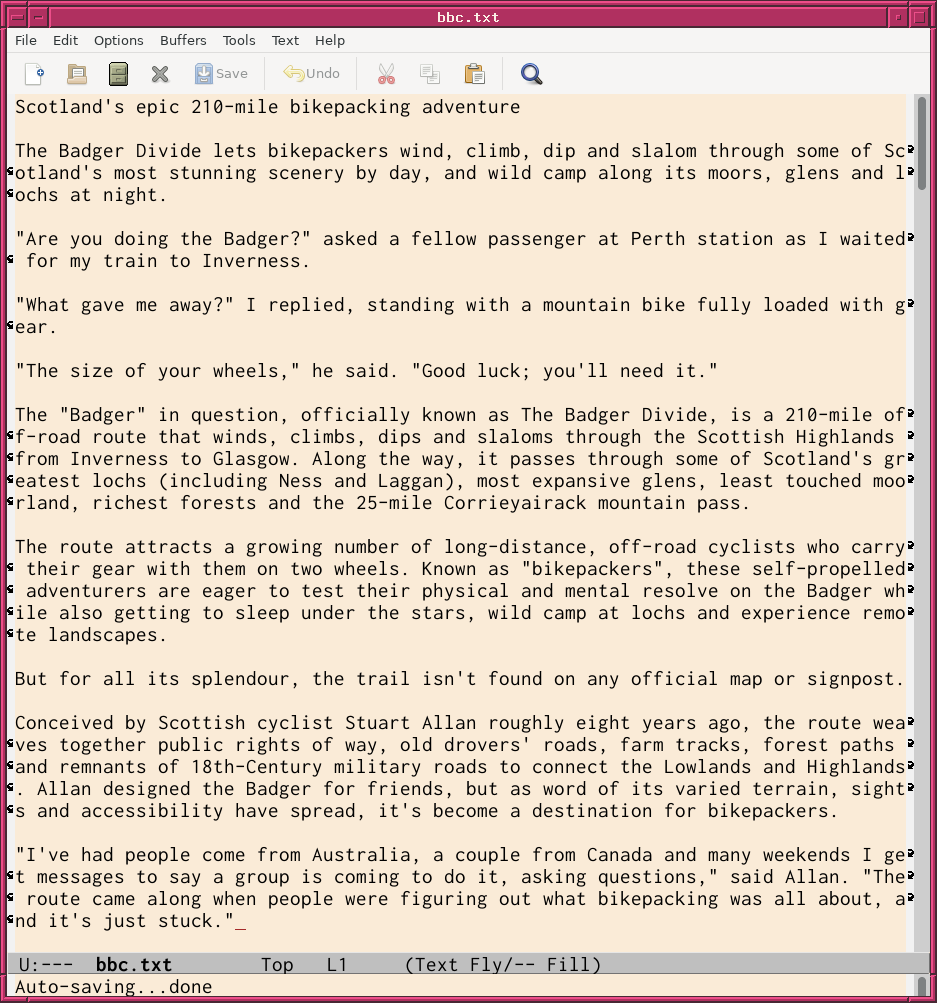
#!/usr/pkg/bin/python3.13 # # Time-stamp: <2025/06/06 18:23:18 (UT+08:00) daisuke> # # importing argparse module import argparse # importing sys module import sys # importing urllib module import urllib.request # importing beautiful soup module import bs4 # importing subprocess module import subprocess # initialising a parser descr = f'Downloading BBC news article and generating MP3 file' parser = argparse.ArgumentParser (description=descr) # adding arguments list_gender = ['female', 'male'] dic_voice = { 'female': 'en-GB-SoniaNeural', 'male': 'en-GB-ThomasNeural', } parser.add_argument ('-u', '--url', default='', \ help='URL of BBC news article') parser.add_argument ('-t', '--text', default='bbc.txt', \ help='output text file') parser.add_argument ('-a', '--audio', default='bbc.mp3', \ help='output audio file') parser.add_argument ('-g', '--gender', choices=list_gender, default='female', \ help='gender of synthesised speech (female or male)') parser.add_argument ('-e', '--edgetts', default='edge-tts', \ help='edge-tts command') # parsing arguments args = parser.parse_args () # input parameters url_bbc = args.url file_text = args.text file_audio = args.audio voice_gender = args.gender voice_name = dic_voice[voice_gender] command_edgetts = args.edgetts # checking URL if not ('https://www.bbc.com/' in url_bbc): # printing a message print ("ERROR:") print ("ERROR: specified URL is not for BBC news article.") print ("ERROR:") # exit sys.exit (0) # fetching HTML file with urllib.request.urlopen (url_bbc) as fh_in: html_bbc = fh_in.read ().decode ('utf-8') # creating BeautifulSoup object soup = bs4.BeautifulSoup (html_bbc, 'html.parser') # extracting article title and body html_article_title = soup.find ('article').find ('h1') html_article_body = soup.find ('article').find_all (attrs={"data-component": "text-block"}) # writing extracted plain text into a file with open (file_text, 'w') as fh_out: fh_out.write (html_article_title.get_text ()) fh_out.write (f'\n\n') for i in range (len (html_article_body)): fh_out.write (html_article_body[i].get_text ()) fh_out.write (f'\n\n') # executing edge-tts command to make MP3 file command_create_mp3 = f'{command_edgetts} -f {file_text} --write-media {file_audio} --voice {voice_name}' subprocess.run (command_create_mp3, shell=True)
期待通りに動作してくれたでござる。
|
|---|
Beautiful Soup はとても便利だということがわかったでござる。